Wikipedia on UTF-8
I found the Wikipedia article on UTF-8 a bit wordy, but at parts very beautiful. Here’s are the parts I find most useful, with minor edits.
Design
The design of UTF-8 can be seen in this table of the scheme as originally proposed by Dave Prosser and subsequently modified by Ken Thompson (the x characters are replaced by the bits of the code point):
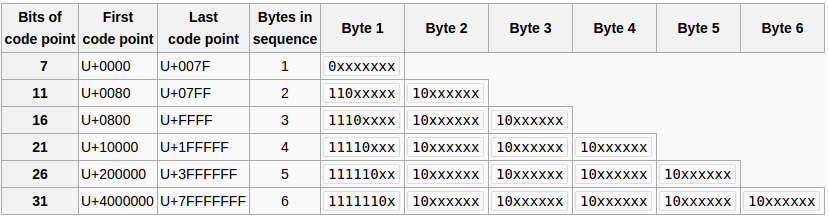
The first 128 characters (US-ASCII) need one byte. The next 1,920 characters need two bytes to encode. This covers the remainder of almost all Latin alphabets, and also Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic, Syriac and Tāna alphabets, as well as Combining Diacritical Marks. Three bytes are needed for characters in the rest of the Basic Multilingual Plane (which contains virtually all characters in common use). Four bytes are needed for characters in the other planes of Unicode, which include less common CJK characters, various historic scripts, mathematical symbols, and emoji (pictographic symbols).
Examples
Consider the encoding of the Euro sign, €.
- The Unicode code point for "€" is U+20AC.
- According to the scheme table above, this will take three bytes to encode, since it is between U+0800 and U+FFFF.
- Hexadecimal
20ACis binary0010000010101100. The two leading zeros are added because, as the scheme table shows, a three-byte encoding needs exactly sixteen bits from the code point. - Because it is a three-byte encoding, the leading byte starts with three 1s, then a 0 (
1110...) - The remaining bits of this byte are taken from the code point (
11100010), leaving ...000010101100. - Each of the continuation bytes starts with
10and takes six bits of the code point (so10000010, then10101100).
The three bytes 11100010 10000010 10101100 can be more concisely written in hexadecimal, as E2 82 AC.
The following table summarises this conversion, as well as others with different lengths in UTF-8. The colors indicate how bits from the code point are distributed among the UTF-8 bytes. Additional bits added by the UTF-8 encoding process are shown in black.

Why is Unicode Awesome?
The great features of this scheme are as follows:
- Backward compatibility: One-byte codes are used only for the ASCII values 0 through 127. In this case the UTF-8 code has the same value as the ASCII code. The high-order bit of these codes is always 0.
- Clear distinction between multi-byte and single-byte characters: Code points larger than 127 are represented by multi-byte sequences, composed of a leading byte and one or more continuation bytes. The leading byte has two or more high-order 1s followed by a 0, while continuation bytes all have '10' in the high-order position.
- Self synchronization: Single bytes, leading bytes, and continuation bytes do not share values. This makes the scheme self-synchronizing, allowing the start of a character to be found by backing up at most five bytes (three bytes in actual UTF‑8 per RFC 3629 restriction, see above).
- Clear indication of code sequence length: The number of high-order 1s in the leading byte of a multi-byte sequence indicates the number of bytes in the sequence, so that the length of the sequence can be determined without examining the continuation bytes.
- Code structure: The remaining bits of the encoding are used for the bits of the code point being encoded, padded with high-order 0s if necessary. The high-order bits go in the lead byte, lower-order bits in succeeding continuation bytes. The number of bytes in the encoding is the minimum required to hold all the significant bits of the code point.